Analyzing Job Descriptions to Fine-Tune the Process
The Setup
Job Searching can be tough, and one of the hardest parts is trying to understand what it is you’re really looking for, and how to get it once you find it. For this project, I wanted to identify key words in job descriptions I was are interested in to optimize my resume and keyword searches. Secondarily, I wanted to make the process generalizable so that others could benefit. I believe that we all benefit when we share this kind of knowledge. For a link to the github page, see below. There’s also a Google Drive folder that can be copied so that you can easily drop in your files and get crunching.
Methodology
Here’s how I did it.
Simple Text Cloud
The basic idea is to load in job postings from Word or other text documents. Once the data is loaded up, I can simply count words to find the common thread in the posts that I’m interested in. Here’s what the visualization looks like:

So this is fairly helpful. I have some good jargon to work with, but a lot of the terms (like ‘teamwork’) are pretty generic. Let’s see if we can improve on this a bit.
Word Significance
A refinement of the above, the model then looks in a corpus of basic conversational text to create a custom of TF-IDF vector. The current text base is from some random Reddit pages collected in September 2018 for a different project (The source subreddits for each post are in the file). This corpus is then used to develop a word frequency baseline.
The counts for each word from the first part are then divided by relative frequency from the Reddit corpus to get a ‘Significance’. The idea is that we don’t just want the overall count of a word - just about every post out there is looking for ‘teamwork’. By identifying rare words that occur frequently in the job posts you’re looking at, you can get a sense of what defines each post, and what makes it unique. Here’s what that looks like:
From this we can start to see some more interesting patterns emerging. There are skills (SQL, Python) and expertise areas (refine, Tableau) that begin to emerge as important.
Comparison and Conclusion
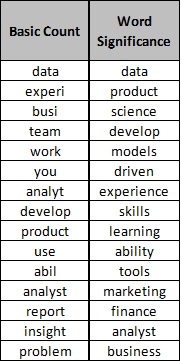
The column on the left is top words, ranked by the basic count of word stems. On the right is the second methodology, weighting words by relative frequency.
Looking at this table, both versions of the analysis have value.
The basic count is a quick checklist of must haves in a cover letter or resume. Somewhere, you have to mention team-work, insights, reporting ability, the product.
What the Word Significance results start to do is suggest a more natural sentence with real meaning. For example, I can look down the column and see the sentence “Develop data-driven models to improve customer experience and improve product” or “Experience leveraging data science tools to craft financial/marketing analysis”. More abstractly, I can see that the job postings in my set are formatted to look for the application of general skills to achieve a result in a specific business area.
When I go to craft line items for my resume, each bullet can probably safely be condensed to read like “Applied skill and knowledge of tool to achieve result in area.” Each of these generic items can be filled in from a bag of skills I would like to present.
This also gives a framework to condense down vague job postings to identify what the actual ask is. I encourage you to take a look and run the notebooks below for yourself, and try to improve on the analysis. Happy hunting!
Source files
Jupyter Notebook on Google Drive
If copying the Google Drive notebook, be sure to copy the notebook and all files in the Data subfolder. To insert your own job descriptions, make an individual word document for each, with the naming convention
Job Name - Company Name